mysql模糊查询like优化
1、前言
在我存储题库的时候,搜题肯定要用模糊搜索题目,但一般情况下 like 模糊查询的写法为(field 已建立索引)
SELECT `column` FROM `table` WHERE `field` LIKE '%keyword%';
但是问题来了,因为是模糊搜索,一旦数据过大,查询速度将会非常慢,同时请求过多还会导致服务器负载(我的题库 API 接口就是这样),宝塔面板如下
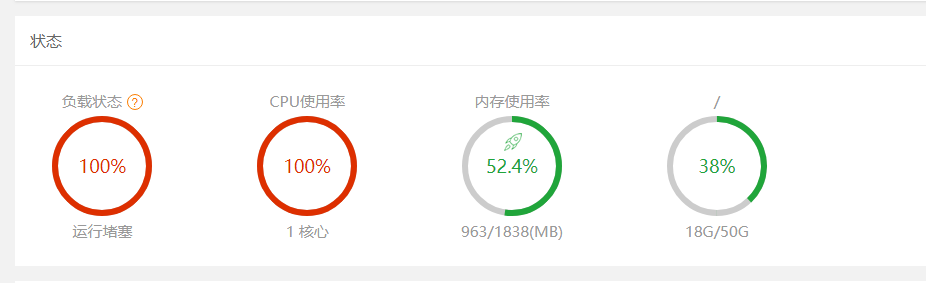
所以,要保证多并发查题查题的同时,有能快速搜索到对应的题目,数据库提速就显得尤为重要了,在翻看相关文章解决了我这一问题。
参考链接 MySql 模糊查询 LIKE 优化
2、LIKE '%keyword%'
在没怎么了解 LIKE 模糊查询前,一直以为 LIKE 会用到索引,搜索了相关资料才发现,%keyword% 对应这种的模糊搜索,用不到索引,而是全表扫描,也就导致查询速度特别慢。
3、添加前缀
上面�写到 %keyword% 用不到索引,但如果给字段添加一个前缀文本,比如我这里添加为 KZTK_(愧怍题库),然后拼接为 KZTK_%keyword%
4、给字段添加前缀
UPDATE kz_answer SET `topic` = CONCAT('KZTK_',topic)
然而。。。
然而上面的那些操作对百万级别的数据来说几乎没有任何速度的提升,因为 Like 搜索本来就很慢。上面所说的需求其实更应该换一个数据库,也就是 elasticsearch。想制作一个搜索引擎似的数据库,并且有高效的查询速度,并且可针对关键词,模糊搜索,正好就符合这个场景。